I trained (the world's first?!) ASMR generation model on 400 hours of ASMR, and it sounds like ASMR... if a robot alien was doing it 😂 🤖 👽
Here's one sample, which gives me a tiny tingle:
I've long been interested in ASMR generation, because I believe it holds the secrets to creating potent digital experiences that can help humans thrive, all the way from curing insomnia, to helping people become enlightened faster.
In this blog post, I'll cover:
- What ASMR is
- The results from my mini ASMR generation experiment
- Why ASMR generation is particularly interesting
- Next steps to improve ASMR generation
What is ASMR?
This article probably makes no sense to you if you're not familiar with ASMR. So, let's go over it. From the Wikipedia page:
An autonomous sensory meridian response (ASMR) is a tingling sensation that usually begins on the scalp and moves down the back of the neck and upper spine. A pleasant form of paresthesia, it has been compared with auditory-tactile synesthesia and may overlap with frisson. ASMR is a subjective experience of "low-grade euphoria" characterized by "a combination of positive feelings and a distinct static-like tingling sensation on the skin." It is most commonly triggered by specific auditory or visual stimuli, and less commonly by intentional attention control.
Basically:
- You hear a sound, typically a whisper, soft spoken voice, tapping, brushing, scratching, or other tactile / treble-heavy type of sound.
- You get tingles down your spine, much like what you'd get from one of those scalp massager tools.
- This tingle has a relaxing quality, which lowers sleep onset latency.
This unfortunately doesn't work for everyone. It's not known how many people can experience ASMR tingles, but I'd guesstimate it's somewhere between 5% and 20% of the population.
Early results in ASMR generation with AI
I was looking for the best architecture to use for ASMR generation and found MusicGen, a model originally trained on 20k hours of music. This model was (1) good at high frequencies, (2) a simple architecture which I could easily understand and reimplement, and (3) could generate in almost-real-time, so it seemed perfect for the job.
I then finetuned it on ~400 hours of ASMR, and it did a decent job of generating ASMR.
My dataset was almost entirely unlabelled, so there's no way to condition it. Despite that, in my random samples, I've found that it can kind of do:
Mic touching:
Brushing:
Whispering:
Soft spoken:
Tapping:
Tibetan singing bowls?:
The future of ASMR is beyond your wildest dreams
So why care about ASMR generation? Because we're underestimating how good digital superstimulus will become.
Let's think step by step:
Let's say TikTok is like Digital Crack: a short-lived drug that does nothing but keep you wanting more. So is Instagram, YouTube, and Reddit, and they have been for many years.
Anything with a recommendation engine that optimizes for user minutes will by default become Digital Crack. And user minutes is a really practical and strong optimization signal.
ASMR is fundamentally different than Tiktok. Tiktok works on anticipation. ASMR works on relaxation. Good ASMR gets low user minutes, because the user falls asleep. And ASMR is new, first coined in 2010, so it hasn't had much time to become optimized yet. But with enough optimization, ASMR could become Digital Ambien or Digital Xanax - just as strongly as TikTok is Digital Crack.
RLHF for ASMR tingles
So how do you optimize, when user minutes can't be the signal? Tingles!
ASMR really has two effects: (1) it gives you tingles, and (2) it puts you to sleep.
And the most powerful thing about ASMR is that the relaxation-effect depends upon the tingle-effect. If you get tingles, you'll fall asleep. And if you don't, you won't.
And tingles happen fast, and frequently. So we've got a short feedback loop, which, barring excessive goodharting, is an extremely good proxy for the slower, desired outcome (sleepiness).
Tingles happen on the scale of a few seconds, whereas "whether a video puts you to sleep" is a binary outcome on the scale of a whole video (20-30 minutes). Going from measuring "sleep onset" to "tingles" effectively gives us 100 times more signal to work with.
So we have a really clear, short feedback loop, that we can use to train personalized tingle-maximizing models, via RLHF. But first, we must train a better foundation model!
Towards digital Ambien and beyond 🚀✨
The fact that ASMR exists is mind-blowing. How can a type of .mp3 file trigger a physical sensation of tingles on the skin, which then puts you to sleep? This is effectively synaesthesia. But, widespread - and useful! (for treating mild insomnia)
And somehow, we didn't discover this until the early 2010s, when the creator economy had matured enough to start producing high-quality niche content.
Through a combination of people leaving bigger footprints online, and AIs becoming more efficient at extracting subtle patterns from those footprints, we'll see new digital experiences emerging at an ever-faster rate.
With this trend, we should see more unexpected hits like ASMR. We'll also see models creating things that we have no words for yet, because the space of all possible experiences is vast.
There will be audio clips that cure insomnia (this project aims at that). Helmets that put you into Jhana. AI meditation instructors that help you awaken 100x faster than what's currently possible. Social apps that create better social experiences than ever possible before, not more isolation like current ones do.
This future is going to be beautiful! 🔮
Next steps
As it stands, this model is fun but not super useful. For now, I'd still prefer to go on YouTube and watch actual ASMR videos, instead of asking ASMRGen to generate new ones for me.
This will change with the following steps:
- Collect more data: I've scraped a dataset orders of magnitude larger than this one.
- Create a world-class labelling tool: The more smart tricks, the better the tools, the faster you can create high quality labels. And high quality labels allow us to condition the trained model precisely. Read more.
- Label the dataset (or just a fraction): Even with the best tooling in the world, the grunt work is irreplaceable. So, I've been spending my evenings labelling the dataset.
- Train a bigger, better model on all this data! If trained for ~100x longer (~400 GPU-hours), I think we'll start to see something really good. The reasoning for that is, the MusicGen model is trained for an estimated ~640 hours, and has strong results. ASMR seems comparatively easier, and so something in that range should get us there.
If you want to help out, and happen to have some extra A100s lying around, DM me on Twitter or send me an email at louislva@gmail.com! 🙏
Labelling the dataset
When training ML models, the quantity & quality of the data is usually key. Effectively this means you want a dataset with a very high bar for quality, and then you want it to be as big as possible.
This means that you'll have to manually review or label a lot of data, and that you want tools that:
- Do most of the work for you (i.e. autolabelling beforehand)
- Make you better at labelling data (e.g. noticing things you might not have noticed otherwise)
- Help catch your errors (review processes, automated checks, etc)
I've found that bespoke tooling often beats more general tooling, since you can employ heuristics & tricks that are specific to your data. For an example of this, I tweeted a demo video of the ASMR-annotation tool. You can watch that if you like, or just read the list tricks I used to make a great labelling tool for ASMR here:
Label transcripts, not audio. They're easier to navigate. As I was playing around with the interface, I found that seeking in audio or video was confusing and slow - and I'm someone with 1000s of hours of experience editing audio and video! 😬
So then I played around with transcribing the video with DeepGram, adding "..." where there's silence or non-speech sounds, and then allowing you to seek by dragging on the transcript. This was a lot faster, since you're now throttled by reading speed as opposed to listening speed. And it only cost like $0.10 per video!
Apply labels to all spoken material, since it's typically consistent throughout an ASMR video. People's voices are a big part of ASMR, and there are a lot of things you can describe them as:
- Whispering <> soft spoken
- Male <> female
- Accent
- Pitch, sound, tone, crispness, etc.
And we already know exactly when speech starts and ends, since we have the transcript! So you can just label that once, and have it automatically applied to all spoken parts with very high precision.
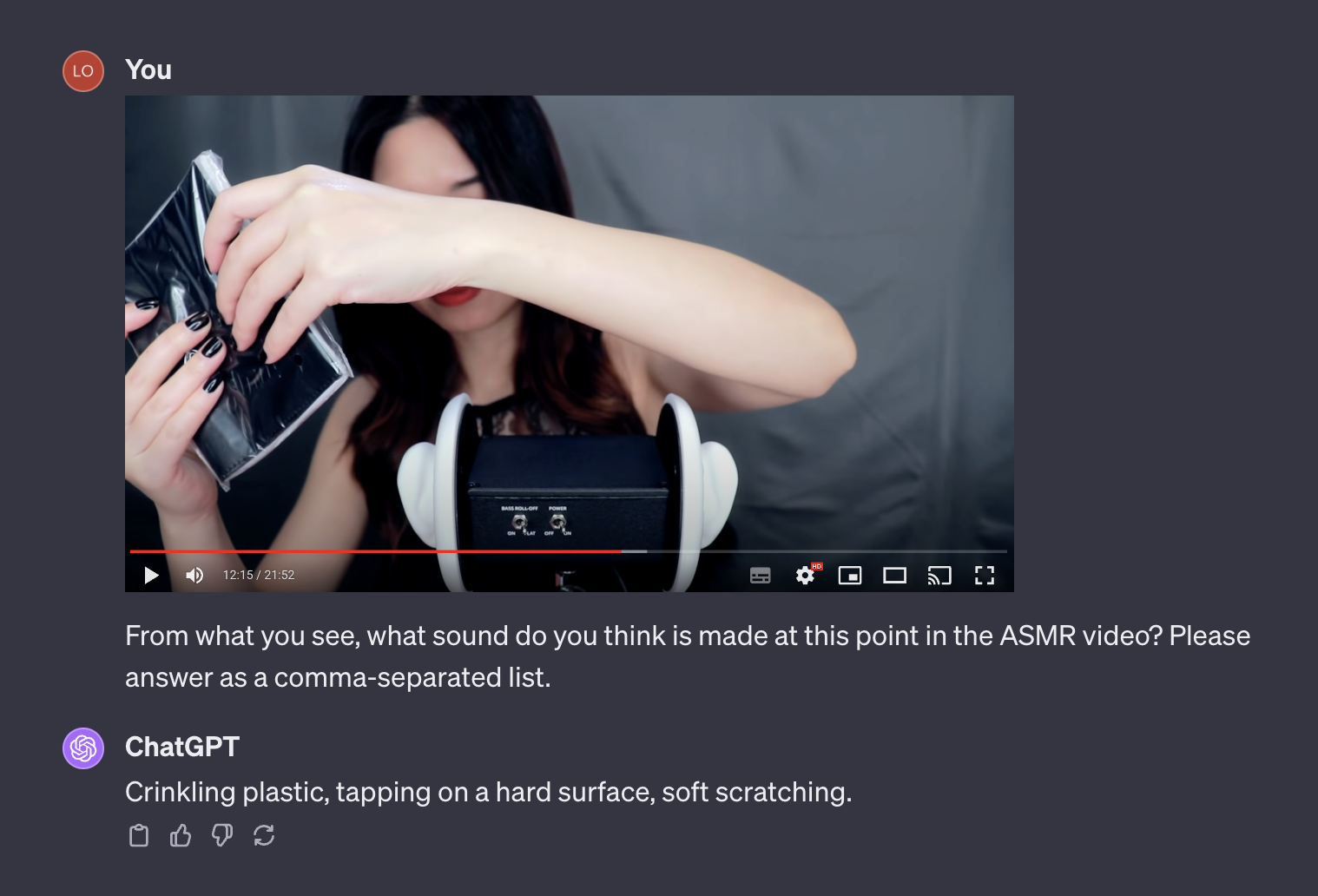
Autolabel sounds by looking at the video with GPT-4V. Out of Language, Vision, and Audio, I would argue audio is still behind in terms of generality. We have pretty good transcription, but still nothing like GPT-4 for audio. However - GPT-4V still has a pretty good idea of what sounds different objects make, and can infer most of it from looking at frames from an ASMR video.
Label each feature individually, and then sample combinations of labels for different windows. If you label each trigger with the exact timespan it occurs in, you can sample 30 second windows with different combinations of triggers. E.g. from 0:00 to 0:30 there's Trigger A, and from 0:30 to 1:00 there's Trigger B. If you sample 0:00 to 0:30 you get "Trigger A", if you sample 0:30 to 1:00 you get "Trigger B", but if you sample 0:15 to 0:45, you get "Trigger A + Trigger B". If you're training for many epochs, your neural network can get a lot more information out of the same labelled data.
Make the UX good. When quickly iterating on data labelling tools, it's fine to skimp on visuals, but never on user experience. You should still take the effort to make it intuitive, add keyboard shortcuts, and make sure it's not glitchy. The faster and better the UX, the faster you can label, and the more you can accomplish. Oftentimes, this justifies developing something a bit more slowly in Next.js vs using something quick like Streamlit (although that's also very often useful too!)
100 random samples:
ASMR sample 0:
ASMR sample 1:
ASMR sample 2:
ASMR sample 3:
ASMR sample 4:
ASMR sample 5:
ASMR sample 6:
ASMR sample 7:
ASMR sample 8:
ASMR sample 9:
ASMR sample 10:
ASMR sample 11:
ASMR sample 12:
ASMR sample 13:
ASMR sample 14:
ASMR sample 15:
ASMR sample 16:
ASMR sample 17:
ASMR sample 18:
ASMR sample 19:
ASMR sample 20:
ASMR sample 21:
ASMR sample 22:
ASMR sample 23:
ASMR sample 24:
ASMR sample 25:
ASMR sample 26:
ASMR sample 27:
ASMR sample 28:
ASMR sample 29:
ASMR sample 30:
ASMR sample 31:
ASMR sample 32:
ASMR sample 33:
ASMR sample 34:
ASMR sample 35:
ASMR sample 36:
ASMR sample 37:
ASMR sample 38:
ASMR sample 39:
ASMR sample 40:
ASMR sample 41:
ASMR sample 42:
ASMR sample 43:
ASMR sample 44:
ASMR sample 45:
ASMR sample 46:
ASMR sample 47:
ASMR sample 48:
ASMR sample 49:
ASMR sample 50:
ASMR sample 51:
ASMR sample 52:
ASMR sample 53:
ASMR sample 54:
ASMR sample 55:
ASMR sample 56:
ASMR sample 57:
ASMR sample 58:
ASMR sample 59:
ASMR sample 60:
ASMR sample 61:
ASMR sample 62:
ASMR sample 63:
ASMR sample 64:
ASMR sample 65:
ASMR sample 66:
ASMR sample 67:
ASMR sample 68:
ASMR sample 69:
ASMR sample 70:
ASMR sample 71:
ASMR sample 72:
ASMR sample 73:
ASMR sample 74:
ASMR sample 75:
ASMR sample 76:
ASMR sample 77:
ASMR sample 78:
ASMR sample 79:
ASMR sample 80:
ASMR sample 81:
ASMR sample 82:
ASMR sample 83:
ASMR sample 84:
ASMR sample 85:
ASMR sample 86:
ASMR sample 87:
ASMR sample 88:
ASMR sample 89:
ASMR sample 90:
ASMR sample 91:
ASMR sample 92:
ASMR sample 93:
ASMR sample 94:
ASMR sample 95:
ASMR sample 96:
ASMR sample 97:
ASMR sample 98:
ASMR sample 99: